



grep、sed和awk被称为 Linux 三剑客,它们在文本处理和数据操作方面极其强大且常用。
Linux 三剑客在文件处理中的作用:
grep(数据查找定位):文本搜索工具,在文件中搜索符合正则表达式的文本内容,并打印匹配的行。
awk(数据切片):文本处理工具,主要用于对结构化数据进行格式化和拆分处理,进行数据统计和报告生成;
sed(数据修改):流编辑器,对文本进行插入、删除、替换、提取等操作。
grep
grep 的功能:
文本模式搜索
正则表达式匹配
高亮显示匹配内容
支持递归搜索目录
基本格式
grep [选项参数] pattern [file...]pattern:过滤条件,可以是正则表达式file:要搜索的文件(一个或多个),若不指定文件,grep 会从标准输入读取选项参数:
-i:不区分大小写-v:显示不被匹配到的行,相当于反向匹配-r 或 -R:递归搜索目录下的所有文件-l:仅显示包含匹配模式的文件名-L:仅显示不包含匹配模式的文件名-n:显示匹配行与行号-c:只统计匹配的行数-o:只输出匹配到的内容-w:匹配整个单词-A <显示行数>:除了显示符合匹配的那一列之外,并显示该行之后的内容-B <显示行数>:除了显示符合样式的那一行之外,并显示该行之前的内容-C <显示行数>:除了显示符合样式的那一行之外,并显示该行前后的内容-e:实现多个选项间的逻辑 or 关系-E:扩展的正则表达式-F:使用固定字符串模式-P:使用 Perl 正则表达式
正则表达式
匹配字符
匹配自身,例如,
graep 'a' file.txt匹配文件中所有包含字符 a 的行点
.匹配任意单个字符(除换行符外),例如,
grep 'a.c' file.txt匹配 a 和 c 之间有一个字符的行字符集
[...][abc]:匹配字符 a、b、c 中任意一个
[^abc]:匹配除 a、b、c 之外的任意字符
[a-z]:匹配从 a 到 z 的任意字符
锚点(^和$)
^:匹配行首,例如,grep '^a' file.txt匹配以 a 开头的行$:匹配行尾,例如,grep 'a' file.txt匹配以 a 结尾的行
转义字符
\用来转义元字符,使其失去特殊含义,例如,
grep '\.' file.txt匹配包含.字符的行
扩展正则表达式字符集(使用grep -E或egrep):
|:逻辑或,匹配左右任意一个表达式例如,
grep -E 'a|b' file.txt匹配包含 a 或 b 的行():分组例如,
grep -E '(abc|def)' file.txt匹配包含 abc 或 def 的行?:匹配前面的字符 0 次或 1 次例如,
grep -E 'colou?r' file.txt匹配 color 或 colour*:匹配前面的字符 0 次或多次例如,
grep -E 'ab*c' file.txt匹配 ac、abc、abbc 等+:匹配前面的字符 1 次或多次例如,
grep -E 'ab+c' file.txt匹配 abc、abbc 等{}{n} 表示匹配前面的字符恰好 n 次
{n,} 表示匹配前面的字符至少 n 次
{n, m} 表示匹配前面的字符至少 n 次,至多 m 次
常用命令举例
假设有一个 file.txt 文件,内容如下:
name,age,sex,salary
Alice,30,女,9000
Bob,25,男,8000
Carol,35,男,7000
Karry,21,女,5000
Ross,40,女,6500
Joan,38,男,10000
Linda,46,女,5000
Lily,26,女,3000
KARRY,27,女,6000基本搜索
# 搜索文件 file.txt 中包含 karry 的行
grep 'Karry' file.txt
忽略大小写
# 搜索文件 file.txt 中包含 karry(不区分大小写)的行。
grep -i 'Karry' file.txt
递归搜索目录
# 递归搜索目录指定中所有文件,查找包含 pattern 的行
grep -r 'Karry' ./multi-thread
显示匹配行号
# 搜索文件 file.txt 中包含 karry 的行,并显示匹配行号
grep -n 'Karry' file.txt
仅显示匹配文件名
# 搜索当前目录下所有 .txt 文件,显示包含 pattern 的文件名。
grep -l 'Karry' *.txt
反向匹配
# 搜索文件 file.txt 中不包含 pattern 的行。
grep -v 'Karry' file.txt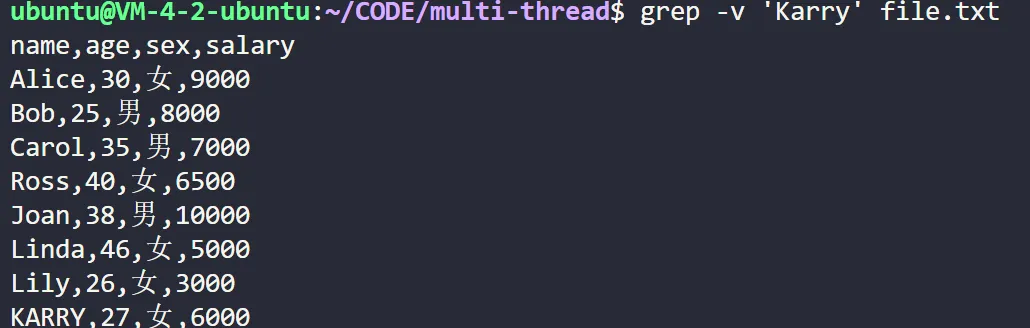
显示匹配行及其之后的行
# 搜索文件 file.txt 中包含 pattern 的行,并显示匹配行及之后的 3 行
grep -A 3 'Karry' file.txt
显示匹配行及其之前的行
# 搜索文件 file.txt 中包含 pattern 的行,并显示匹配行及之前的 3 行
grep -B 3 'Karry' file.txt
显示匹配行及其前后的行
# 搜索文件 file.txt 中包含 pattern 的行,并显示匹配行及其前后的 3 行
grep -C 3 'Karry' file.txt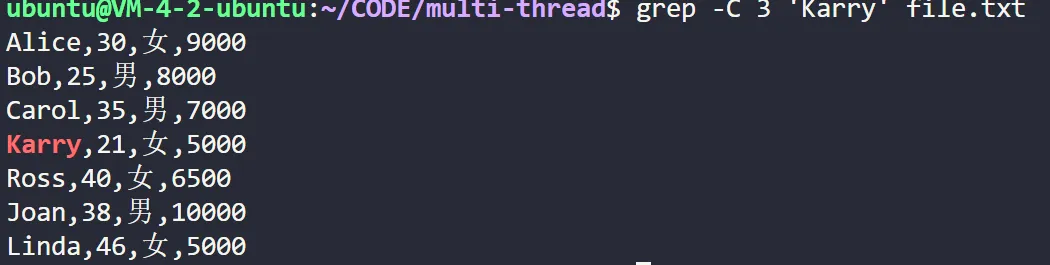
awk
awk 的功能:
字符串处理和替换
数据统计和报告生成
复杂的条件判断和循环处理
数据格式转换
基本格式
awk [选项参数] 'pattern {action}' filepattern:匹配的模式,支持正则表达式action:对匹配上的行要执行的操作常用选项参数:
-F fs指定输入字段分割符,默认是空格或制表符-v var=value为 awk 程序中的变量赋初值-f program-file从指定文件读取 awk 程序
常见的内置变量:
$0:表示完整的输入记录$n:表示指定分隔符后,分隔出的第 n 个字段FS:表示字段输入分隔符,默认以空格为分隔符OFS:表示字段输出分隔符NF:表示字段的个数,即以分隔符分割后,当前行一共有多少个字段NR:表示当前行的行号
常见命令举例
假设有一个 file.txt 文件,内容如下:
name,age,sex,salary
Alice,30,女,9000
Bob,25,男,8000
Carol,35,男,7000
Karry,21,女,5000打印内容
# 打印文件 file.txt 的每一行
awk '{ print }' file.txt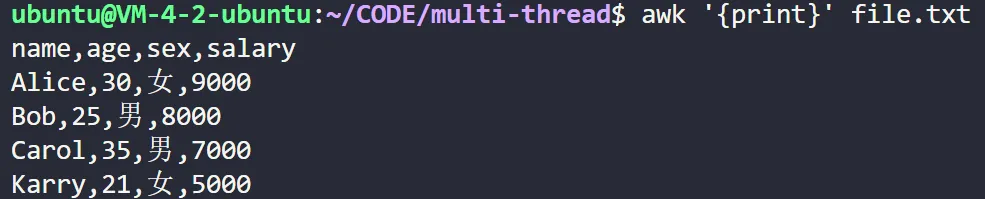
指定字段分割符
假设文件内容用逗号分隔,打印第1、第3个字段:
awk -F ',' '{print $1, $3}' file.txt
使用模式匹配
# 打印包含“Karry”字符串的行
awk '/Karry/ { print }' file.txt
按条件过滤
# 打印第2列字段(age)大于30的人的姓名
awk -F ',' '$2 > 30 { print $1 }' file.txt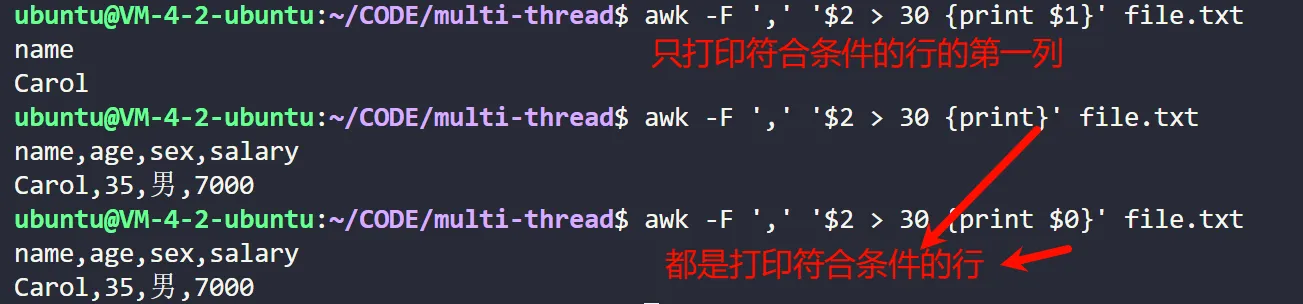
使用变量
# 为变量 age 赋值并使用
awk -F ',' -v age=30 '$2 > age { print $0 }' file.txt
BEGIN和END块
BEGIN块在处理任何输入行之前执行END块在处理完所有输入行之后执行
awk -F ',' 'BEGIN {sum=0} {sum += $4} END {print sum}' file.txt
使用 -f 选项从脚本文件中读取程序
创建一个名为 script.awk 的脚本文件
将以下内容写入到脚步文件中:
#!/usr/bin/awk -f # 使用逗号作为字段分隔符 BEGIN { FS = "," } # 打印第 1 行和第 3 行 { print $1, $3}脚步文件头部:指定用 awk 解释器来运行这个脚步文件
BEGIN 块:设置字段分隔符为逗号
主代码块:打印每行的第 1 和第 3 个字段
运行 awk 脚本文件
方式一:直接用 awk 命令
awk -f script.awk file.txt
方式二:授权脚本文件具有可执行权限,然后运行脚本文件
# 确保脚本文件具有可执行权限 chmod u+x script.awk # 运行脚步文件,并指定输入文件 ./script.awk file.txt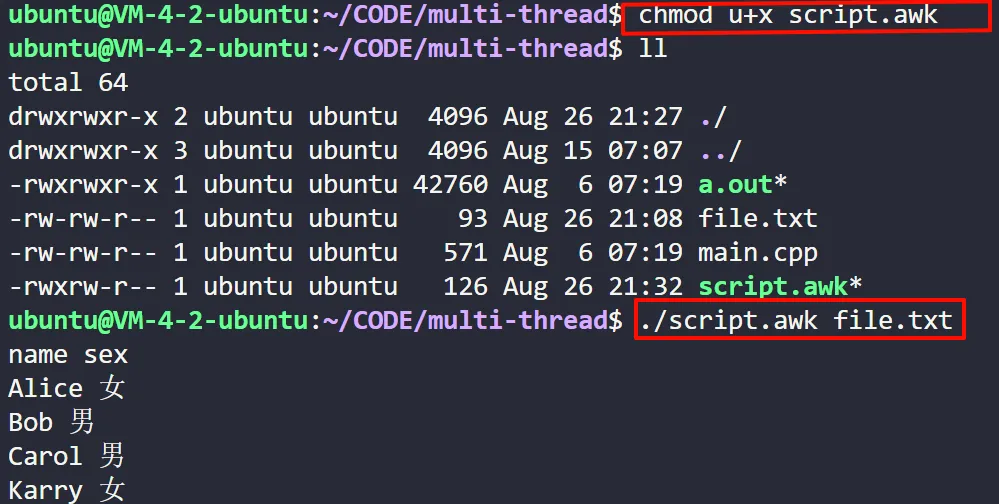
格式转换
# 将 file.txt 文件格式转换为TSV(Tab Separated Values)格式
awk 'BEGIN { FS=","; OFS="\t" } { $1=$1; print }' file.txtBEGIN { FS=","; OFS="\t" }:在处理开始时,将输入字段分隔符设置为逗号,将输出字段分隔符设置为制表符。
1=
1; print:通过赋值操作强制 awk 重新解析字段,然后输出。

提取并格式化指定列
# 提取 Name 和 Age 列,并格式化输出为 "Name: Age years old"
awk -F ',' '{ print "Name: " $1 ", Age: " $2 " years old" }' file.txt
sed
sed 是一个流编辑器,主要用于对文本进行非交互式编辑。它可以进行插入、删除、替换、提取等操作。
sed 的功能:
文本替换和删除
模式匹配和文本插入
支持脚本编写进行复杂的文本处理
数据流操作
基本格式
sed [选项参数] 'script' [file]script:sed 内置的命令字符,主要用于对文件进行增删改查等操作。常见的内置命令字符:
a:表示对文本进行追加操作,在指定行后面添加一行或多行文本d:表示删除匹配行i:表示插入文本,在指定行前添加一行或多行文本p:表示打印匹配行内容,通常与-n同时使用s/正则/替换内容/g:表示匹配正则内容,然后替换内容(支持正则表达式),结尾 g 表示全局匹配
file:要处理的输入文件。若不指定文件,sed 会从标准输入读取
常用选项参数:
-n:表示取消默认的 sed 输出,通常与内置命令p一起使用-e script:直接在命令行上添加要执行的 sed 脚本-f script-file:从脚本文件中读取 sed 命令-i [SUFFIX]:直接修改文件内容,而不是输出到标准输出。可以选择性地备份文件。如果不加-i,sed 修改的是内存数据。-r:使用扩展正则表达式s:将文件视为独立的文件,而不是单一的流
常用命令举例
假设有一个 file.txt 文件,内容如下:
name,age,sex,salary
Alice,30,女,9000
Karry,21,女,5000
Joan,38,男,10000
Lily,26,女,3000
KARRY,27,女,6000文本替换
# 基本替换:将 file.txt 中的第一个匹配 Karry 的字符串替换为 Bob
sed 's/Karry/Bob/' file.txt
# 忽略大小写替换:将 file.txt 中的所有匹配 Karry 的字符串替换为 Bob
sed 's/Karry/Bob/Ig' file.txt
# 全局替换:将 file.txt 中的所有匹配 Lily 的字符串替换为 karry
sed 's/Lily/karry/g' file.txt
# 指定行替换:将 file.txt 中的第4行中匹配 Joan 的字符串替换为 Carol
sed '4s/Joan/Carol/' file.txt
# 行号范围替换:将 file.txt 中的第3到第6行中匹配 KARRY 的字符串替换为 karry
sed '3,6s/KARRY/karry/Ig' file.txt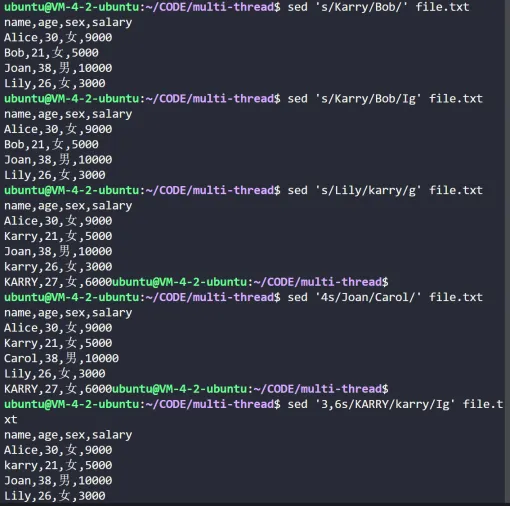
使用 sed 进行文本替换时,默认情况下,sed 只是将替换后的文本输出到标准输出(通常是终端),而不会直接修改源文件。只有使用-i参数进行替换,会修改源文件。
# 替换源文件内容:直接在 file.txt 中替换所有匹配 Karry 的字符串为 Bob
# 并保存修改(修改源文件)
sed -i 's/Karry/Bob/g' file.txt
# 备份原始文件,使用 -i 参数加上备份扩展名来实现
# 进行替换操作之前会创建一个 file.txt.bak 备份文件
sed -i.bak 's/Karry/Bob/g' file.txt文本删除
# 删除某行:删除 file.txt 中的第5行
sed '5d' file.txt
# 行号范围删除:删除 file.txt 中的第3到第4行。
sed '3,4d' file.txt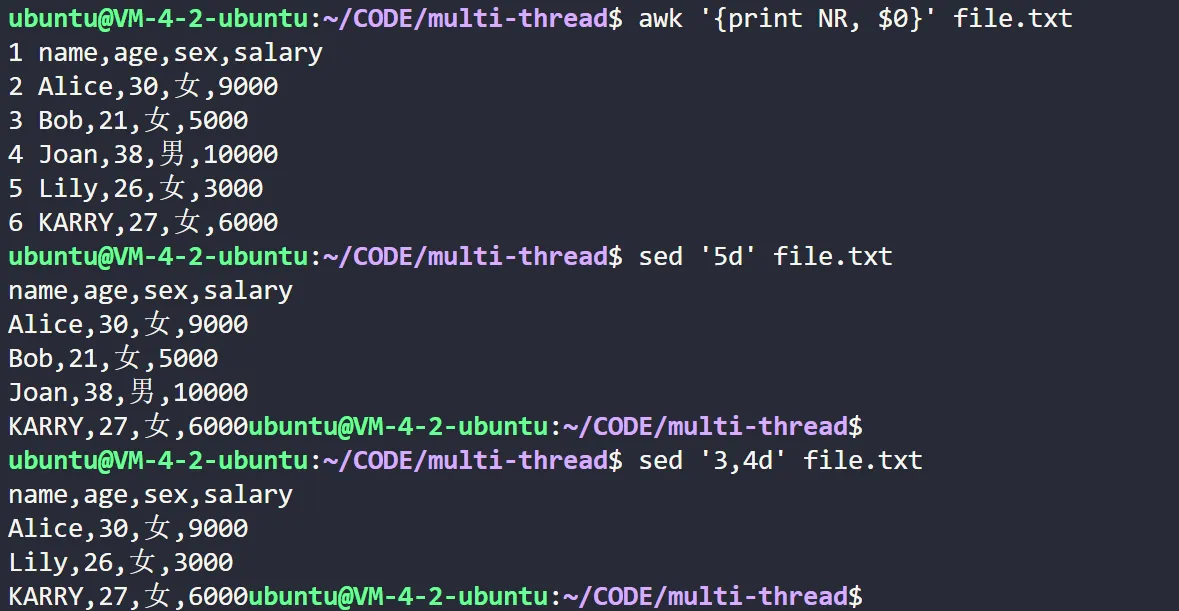
文本插入
# 插入行:在 file.txt 中的第2行之前插入
sed '2i\This is a new line.' file.txt
# 追加行:在 file.txt 中的第3行之后追加
sed '3a\This is a new line.' file.txt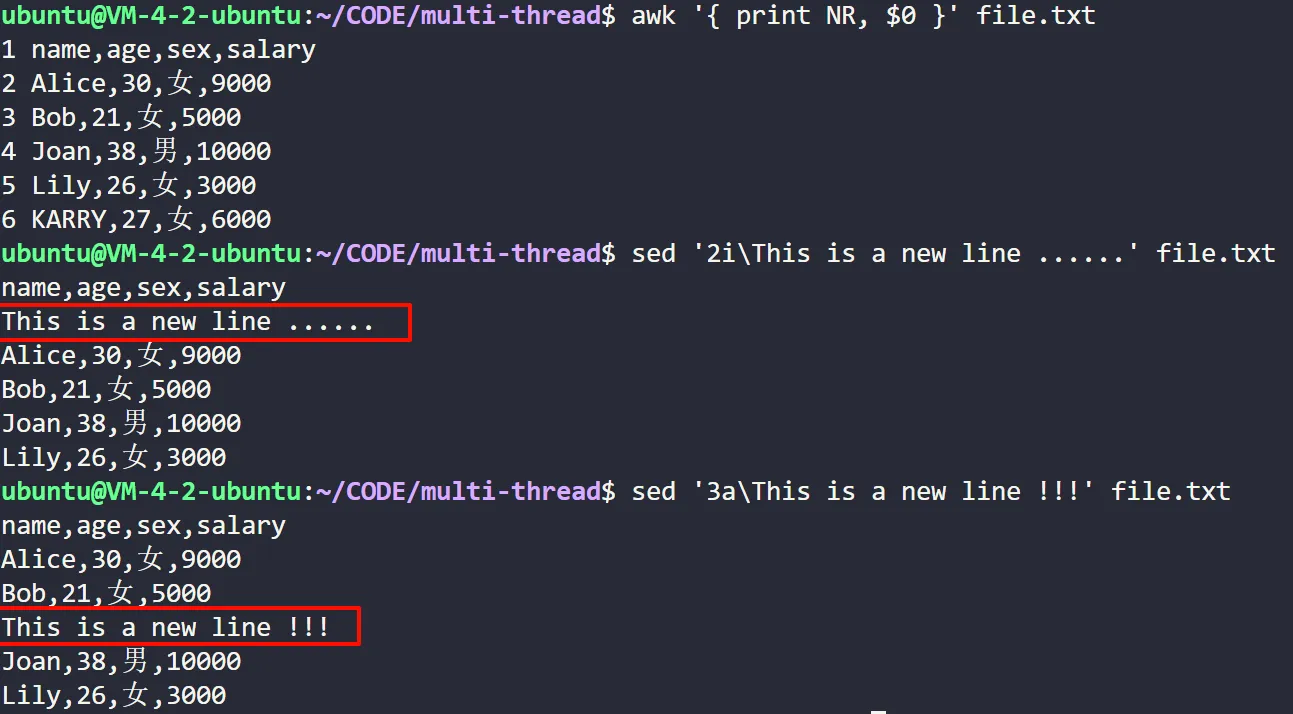
打印模糊匹配的行
# 只打印 file.txt 中包含 Ka 的行
sed -n '/Ka/p' file.txt
从文件读取脚本
创建一个 sed 脚本文件
将以下内容写入文件:
3a\This is a new line.使用 sed 执行脚本文件
sed -f script.sed file.txt
grep、awk、sed常见用法
假设现在有一个日志文件 file.log,其内容如下:
2023-06-25 12:34:56 info User1 logged in
# 连接数据库失败
2023-06-25 12:35:00 error Failed to connect to database
2023-06-25 12:35:05 info User2 logged out
2023-06-25 12:36:10 warn Disk space low
2023-06-25 12:36:15 info User3 logged in
2023-06-25 12:37:00 error Time out过滤空行和注释行后显示文件内容
grep -v '^#' file.log | sed '/^$/d'grep -v '^#' file.log:grep 用于文件中搜索匹配行;-v表示反转匹配,即选出不匹配指定模式的行;'^#'表示匹配以#开头的行。sed '/^$/d':sed 用于逐行处理文本;/^$/是正则表达式,匹配空行(行首紧跟行尾,即行中没有任何字符);d表示删除命令,表示删除匹配的行。
组合命令过滤并格式化输出
使用 grep 过滤日志,awk 格式化输出:
# 从日志文件中提取 ERROR 行,并显示时间
grep 'error' file.log | awk '{print $1, $2}'对数值列进行排序和去重
awk 'print $2' file.log | sort -n | uniqawk 'print $2' file.log打印 file.log 文件每行的第2个字段,awk 默认是空格或制表符作为分隔符
sort -n将上一步输出的数据按数值排序。sort 命令用于对文本行进行排序,
-n选项表示按数值进行排序uniq移除相邻的重复行,输出唯一的行。只有在相邻行重复时,
uniq才会去重,因此通常与sort结合使用。
统计每种日志出现次数
awk '{count[$3]++} END {for (level in count) print level, count[level]}' file.log{count[$3]++}awk 的主处理块,在读取文件的每一行时执行,遇到相同的第三列值时,对应的计数器 count[$3] 自增 1。
END {for (level in count) print level, count[level]}awk 的结束块,在处理完所有行后执行。for 循环遍历 count 数组中的所有键,打印每个键(即第三列的值)及其对应的计数器值(即出现次数)。
grep、awk、sed 三者结合使用
筛选日志文件 file.log中包含 "error" 的行,并从中提取出时间戳和错误信息,然后进行一些格式化处理:
grep "ERROR" log.txt | awk '{print $1, $2, $5}' | sed 's/\[//g; s/\]//g'grep "ERROR" log.txt筛选出包含 "ERROR" 的行
awk '{print $1, 2, $5}'提取每行的第1列、第2列和第5列
sed 's/\[//g; s/\]//g'删除方括号
评论区